2023年8月3日| | 0 Comment
修复黑群晖 DSM7.0 + Btrfs 存储空间/磁盘损毁的问题
意外断电重启后,发现群晖提示硬盘损毁了,但是实际上硬盘还是正常的,S.M.A.R.T. 状态也良好,但是无法写入数据,系统状态报告为“严重”,群晖的程序也拒绝工作。
修复方法
- 通过 SSH 直接登录 root 账号。如果不方便直接登录 root,则执行:
cd /sudo -i
对于虚拟机黑群晖如果SSH挂了也没事,开个管道模式的串口连接(例如
.pipedsm),然后用Putty或者Xshell 以管理员身份运行 连上管道即可。 - 检查有问题的存储池,此时可以看到 sdc3 后面的
[E]表示他现在是错误状态:
cat /proc/mdstat
root@syno:~# cat /proc/mdstatPersonalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] [raidF1]md2 : active raid1 sdc3[0](E)3738594304 blocks super 1.2 [1/1] [E]md1 : active raid1 sdb2[0] sdc2[1]2097088 blocks [12/2] [UU__________]md0 : active raid1 sdb1[0]2490176 blocks [12/1] [U___________]unused devices: <none>
- 执行以下命令停止并用MDADM装载存储池:
synospace --stop-all-spaces # (群晖命令)停止所有存储池mdadm --assemble --scan # 扫描并装在所有存储池
如果这一步没法停止所有存储池,可以尝试先停止所有套件:
# 能停止就不要执行这个命令synopkg list --name | xargs -I"{}" synopkg stop "{}"- 这一步ssh会断开,用telnet不会
- 查看有问题的存储池
md2的信息,记下 Version 和 UUID:mdadm -D /dev/md2 # -D, --detail Print details of one or more md devices
Version : 1.2 # 注意这里Creation Time : Fri Mar 3 21:01:41 2023Raid Level : raid1Name : KDS:2 (local to host KDS)UUID : bf3d8440:bff1633d:8c175723:69d81786 # 注意这里Events : 10Number Major Minor RaidDevice State0 8 35 0 faulty active sync /dev/sdc3
- 执行以下命令停止并修复存储池
md2,这一步我将 UUID 改掉了,不过网上似乎有人不改 UUID 也没什么问题,如果不改 UUID 也可以工作请在评论区反馈:mdadm -Sf /dev/md2 # 停止有问题的存储池md2 -S, --stop deactivate array, releasing all resources.mdadm -Cf /dev/md2 -e1.2 -n1 -l1 /dev/sdc3 -ubf3d8440:bff1633d:8c175723:69d81789 # 1.2为上文version, bf3d8440:bff1633d:8c175723:69d81786 为上文的 UUID 再随便改掉几位,例如把 86 换成 89# -C, --create Create a new array.
- 重启
reboot
- 手动启动存储池。
synospace --start-all-spaces
- 到群晖面板,发现此时存储池由损毁变成只读,此时手动转换为读写模式即可
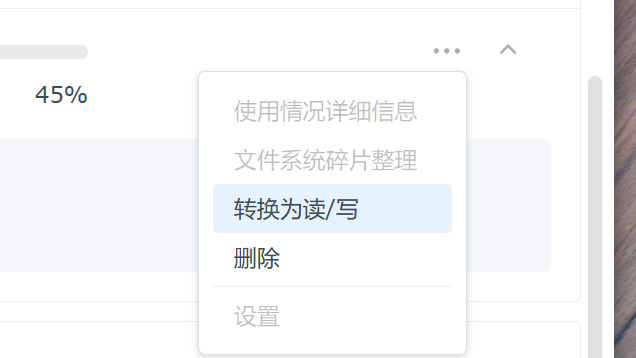
如果之前停用了所有套件:
# 启动所有停止的套件synopkg list --name | xargs -I"{}" synopkg start "{}"